Una nueva dimensión: data warehousing
¿Qué es DW?
La rápida (y no siempre planificada) acumulación de inversiones en TIC ha hecho que muchos sistemas de procesamiento de datos acaben convirtiéndose en un conglomerado de recursos físicos y lógicos técnicamente interoperables, pero no siempre valiosos desde el punto de vista de los negocios. Con frecuencia se observan dispersión y redundancia de datos, discrepancias en los formatos o el marco temporal, dificultades de acceso, y otras carencias que reducen su utilidad para tener una perspectiva amplia y comprensiva de la situación de la empresa, y tomar decisiones con la plasticidad requerida por un contexto dinámico y cambiante.
Data Warehouse es el término (acuñado originalmente por Inmon) con el que nos referimos a una nueva filosofía en cuanto al almacenamiento de los datos transaccionales: se trataría de combinar las fuentes internas y externas para construir un almacén temático, una estructura de datos organizados de acuerdo con la perspectiva de los usuarios, que tiene como finalidad principal aportar un valor adicional a esos datos: convertirlos en conocimiento útil para la gestión y la toma de decisiones. Es, en cierto sentido, una revisión o actualización del concepto tradicional de base de datos, pero también una herramienta completamente nueva desde el punto de vista tanto tecnológico como organizativo.
De la base de datos al concepto de data warehouse
Los TPS habían sido diseñados para "almacenar datos" y, con el paso del tiempo, las organizaciones acumularon volúmenes ingentes de esos datos: clientes, rivales, mercados, operaciones internas, e indicadores y magnitudes de todo tipo. Los sistemas transaccionales también proporcionaban métodos para seleccionar, agregar, etc., lo que en principio se había considerado suficiente; sin embargo esos datos estaban desperdigados en diferentes lugares y formatos heterogéneos, porque los almacenes de datos estaban organizados por aplicaciones o transacciones. Su marco temporal era también relativamente reducido, y comprendían entre unas pocas semanas y varios meses. Los TPS eran sistemas operativos, habían sido diseñados de acuerdo con criterios de eficiencia y operatividad técnica, pero no para responder ágil y flexiblemente consultas complejas de los usuarios, ni para agregar temáticamente los datos, mucho menos para darles un tratamiento estadístico.
Por ejemplo, un directivo podía estar interesado en analizar comparativamente el comportamiento de la facturación en diferentes áreas geográficas; un responsable de zona de una entidad bancaria desearía evaluar comparativamente el desempeño de sus oficinas, considerando criterios como la ubicación (distritos, zonas rurales o urbanas) el perfil de los clientes (renta media, edad, etc.) o su enfoque de negocios (oficinas para empresas vs. oficinas para familias). Las empresas poseían los datos primarios para dar respuesta a estas cuestiones y es probable que sus bases de datos fuesen técnicamente capaces de afrontar las consultas; pero se requerían instrucciones SQL complejas sobre gran cantidad de registros, que consumían tiempo y recursos de cómputo.
Mucha otra información no estaba incorporada al sistema, quizá porque en su momento tenía naturaleza accesoria (y por tanto no había sido registrada), porque no había formado parte de ninguna transacción, o porque tenía carácter externo. Con frecuencia tampoco existían procedimientos concretos para validar los datos, ni para asegurar su coherencia y consistencia.
En definitiva, las empresas poseían amplios volúmenes de datos, pero su utilidad práctica era escasa. Como señaló Codd, "poseer un gestor de base de datos relacional no es sinónimo de disponer de soporte para la toma de decisiones".
Esta situación empezó a representar un problema real para muchas organizaciones en los primeros noventa. Los cambios en la configuración de los mercados y los nuevos modelos de negocio requerían acciones de marketing más enfocadas y personalizadas, también la oferta de productos individualizados acordes con las características concretas de cada cliente; la tecnología de Internet planteaba nuevas oportunidades, pero también amenazas potenciales de rivales de todo el mundo y se empezan a advertir cambios en los modelos de negocio.
En lo que respecta a la tecnología, en este período surgen oportunidades en tres áreas: i) se reduce el coste y aumenta drásticamente la capacidad de los dispositivos de almacenamiento; ii) se desarrollan tecnologías de procesamiento paralelo que permiten incrementar la eficiencia de las bases de datos y hacen posible la ejecución inmediata de consultas complejas como las citadas más arriba, y iii) se abarata la tecnología para compartir recursos a través de la redes. Al mismo tiempo, empieza a estar disponible software comercial para la realización de análisis estadísticos complejos de los datos, y para el desarrollo de herramientas de inteligencia artificial, capaces de identificar patrones y de hallar información oculta en las bases de datos.
Estas sinergias trajeron consigo una nueva filosofía par agestionar los recursos de información: el data warehouse, donde los datos no se almacenan de acuerdo con transacciones sino atendiendo a sus relaciones lógicas. Se organizan de forma temática, en función de conceptos o entidades relevantes para los usuarios: clientes, áreas geográficas, productos, etc. Incluyen además un etiquetado temporal: en lugar de ser actualizados (por tanto, sobreescribiendo las observaciones anteriores de las variables), los datos se agregan para generar series temporales y evaluar tendencias.
El objetivo es facilitar la búsqueda selectiva de información, su análisis segmentado, el empleo de técnicas analíticas de tipo exploratorio (incluyendo herramientas de data mining y de inteligencia artificial) y generar conocimiento.
Elementos de un DW
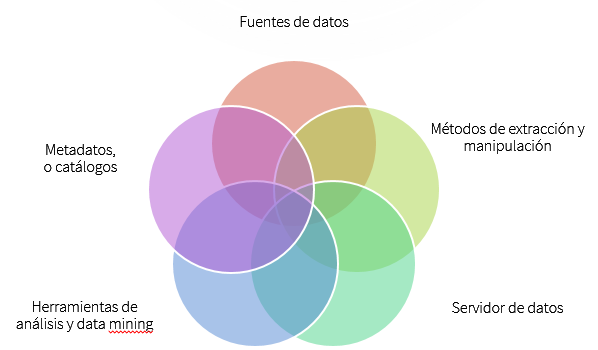
De manera general, un DW combina cinco elementos:
- Fuentes de datos: los orígenes de los que provienen los datos, fundamentalmente los sistemas transaccionales internos, sistemas ofimáticos y de workflow, y fuentes externas
- Módulos para movilizar los datos desde y hacia los sistemas operacionales, y aplicarles transformaciones (seleccionar, agregar, añadir campos, etc.); aquí residen también componentes de reingeniería que realizan operaciones de homogeneización, para hacer posible la integración de datos provenientes de fuentes diferentes y/o expresados en formatos dispares.
- Servidor de datos, en el que residen los recursos de información empleados por el DW. Con frecuencia la organización decidirá desarrollar uno o más DataMart, que son subconjuntos del DW enfocados en los datos y las funciones requeridos por un área o departamento específico; el DM es el resultadod de aplicar métodos similares a los descritos más arriba, para filtrar y transformar los datos relevantes para esa área.
- Métodos para que los usuarios accedan a los datos, incluyendo SQL estándar, análisis multimensional (OLAP), data mining y herramientas de inteligencia artificial
En este contexto una dimensión es un eje o perspectiva de análisis; por ejemplo cuando analizamos el comportamiento de cierta variable durante varios años estamos explorando una serie construida en torno a la dimensión tiempo. Pero puede haber otras dimensiones relevantes, tanto para nosotros como para otros decisores: clientes, tipo de canal, zona geográfica, línea de producto, etc.; por otra parte cada una de ellas es susceptible de otras subdivisiones (clientes individuales o segmentos de clientes; provincias, países, áreas económicas o continentes; meses, semanas o días, etc.). La noción de dimensión implica no solo la existencia de una heterogeneidad de perspectivas, sino también de una estructuración jerárquica interna.
- Catálogos: índices que detallan el tipo de información disponible en el DW y sus relaciones con las entidades reales de interés, por ejemplo "clientes". En el contexto del DW esta identificación se realiza a través de metadatos, que describen la semántica de los datos (nombre, alias para el usuario, área temática), su origen (base de datos, tabla, procedimiento de extracción y conversión, etc.), la fecha en la que fueron creados, su formato, y otras reglas de gestión (por ejemplo, métodos definidos por los usuarios).
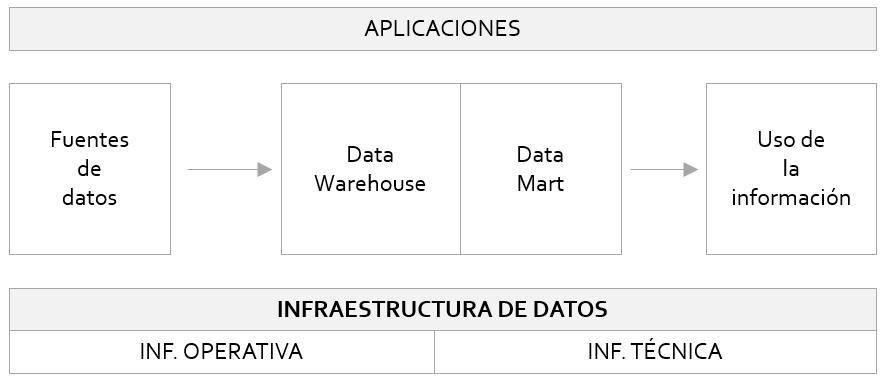
Cada empresa desarrolla su propio DW, en función de sus necesidades específicas de decisión; sin embargo con carácter general hallaremos tres capas (aplicaciones, infraestructura técnica e infrasestructura operativa) y cuatro bloques (fuentes de datos, data warehouse, data mart y usos de la información); esta es la arquitectura de referencia del DW, tal y como fue definida por Grill y Rao (1996).
Data mining
Data Mining (DM) es un conjunto de herramientas y métodos destinados a realizar análisis exploratorios en los datos almacenados en un DW.
Pretende descubrir tendencias, patrones o relaciones ocultas, contrastar hipótesis definidas como reglas analíticas (por ejemplo y = a + b · x) o buscar respuestas a preguntas, todo ello con un cierto grado de proactividad: el objetivo es estos análisis sean realizados por el propio sistema con poca intervención humana; incluso que sea él quien se encargue de supervisar ciertas variables, emitir alertas y sintetizar la posición del negocio en forma de cuadros de mando.
Las aplicaciones de DM son muy variadas, entre ellas las siguientes:
- Descripción de la conducta de compra e identificación de patrones relevantes
- Control de calidad
- Detección del fraude en seguros
- Segmentación de clientes, en el contexto de estrategias de micromarketing
- Análisis del comportamiento de agentes económicos, por ejemplo inversores en un mercado financiero
- Diagnóstico financiero y prevención de la morosidad
- Gestión de proyectos
En este contexto, revisten especial interés los agentes inteligentes.
Obra publicada con Licencia Creative Commons Reconocimiento No comercial Sin obra derivada 4.0