
Vamos a analizar las diferentes posibilidades que tenemos para invertir en dos títulos (A, B) cotizados; en primer lugar calculamos los rendimientos históricos y obtenemos pronósticos de rendimiento y riesgo por extrapolación y empleando los respectivos modelos de mercado; analizamos la composición del riesgo, y finalmente formulamos los modelos de Markowitz y Sharpe.
Rendimientos históricos y pronóstico por extrapolación
Observamos durante cuatro días el comportamiento del precio de dos acciones (A, B) y del índice del mercado en el que cotizan ambos títulos. Los precios de cierre son los siguientes:
| Título A | Título B | Mercado | |
| Día 1 | 4 | 25 | 131 |
| Día 2 | 3 | 28 | 122 |
| Día 3 | 4 | 22 | 148 |
| Día 4 | 5 | 26 | 150 |
Vamos a estimar rendimientos por sesión, en este caso un rendimiento diario. A partir de esta serie (y permitiéndonos la licencia didáctica de tratar una serie tan corta), estimaremos la rentabilidad media y el riesgo históricos para el título A.
Más abajo se ofrecen dos hojas de cálculo para comprobar sus resultados o simular otros valores numéricos
El día 2 las acciones A se han depreciado en 1€, lo que significa una rentabilidad igual a -1/4 = -0,25; el día 3 las acciones se aprecian, nuevamente en 1€, generando una rentabilidad del 33% (1/3 = 0,33).
| PA | rAt | |
| Día 1 | 4 | |
| Día 2 | 3 | -0,25 |
| Día 3 | 4 | 0,33 |
| Día 4 | 5 | 0,25 |
El rendimiento cambia día a día, dependiendo de los cambios (aleatorios) que experimenta la cotización; si tuviésemos que describirlo brevemente, podríamos afirmar que, en promedio, ha sido el 11,11% diario:
![]()
Pero obviamente el rendimiento ha tomado valores dispares, desde el -25% del día 2 hasta el 33% del día 3; los cambios de precio son aleatorios, de ahí que exista un riesgo que podemos medir en forma de dispersión estadística: la varianza del rendimiento ha sido σ2A = 6,64% y la desviación típica σA = 25,76%.
Una extrapolación se basa en la hipótesis de que, si las condiciones del título y su entorno no cambian, podemos anticipar que el rendimiento futuro será aproximadamente igual al promedio histórico, y el riesgo aproximadamente igual a la dispersión histórica. Es importante recodar, especialmente en el caso de muestras pequeñas (aproximadamente, menos de 250 observaciones), que el estimador insesgado de la varianza es la cuasivarianza: en nuestro caso el tamaño de la muestra es solo una licencia didáctica, de manera que vamos a emplear la varianza y la desviación típica; en una situación real, no hay ninguna razón práctica o económica que impida utilizar series con varios centenares de observaciones, donde la diferencia entre la varianza y la cuasivarianza es irrelevante.
| PAt | rAt | (rAt - rAt*)2 | |
| Día 1 | 4 | ||
| Día 2 | 3 | -0,2500 | 0,1304 |
| Día 3 | 4 | 0,3333 | 0,0494 |
| Día 4 | 5 | 0,2500 | 0,0193 |
| Suma | 0,3333 | 0,1991 | |
| rAt* | 0,1111 | ||
| σ2 | 0,0664 | ||
| σ | 0,2576 |
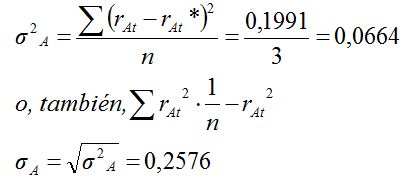
No podemos conocer con certeza cuál va a ser el comportamiento del precio de A en la próxima sesión; pero si tenemos que formular un pronóstico con base en la serie histórica, podríamos confiar en un rendimiento medio esperado del 11% con un riesgo del 25,76%, medido por la desviación típica.
Observe que, manteniendo la presunción de que los rendimientos se distribuyen de manera asintóticamente nornal, el conocimiento de la media y la desviación típica nos permite responder preguntas como ¿qué probabilidad hay de que el rendimiento de mañana sea superior (o inferior) un determinado umbral? También, establecer el intervalo de confianza para la media, que es el rango dentro del cual debería estar el rendimiento de mañana, con cierto grado de confianza.
Hoja de cálculo
¿Qué ocurre si combinamos A y B en una cartera?
Las características de la cartera resultante al combinar varios títulos dependen de i) los estadísticos de los títulos; ii) las proporciones en las que se combinan; y iii) el grado de asociación que exista entre los rendimientos.
La "relación estadística" entre dos variables aleatorias puede medirse a través del coeficiente de correlación de Pearson: ρAB = σAB / (σA · σB ), siendo σAB la covarianza entre ambos rendimientos:
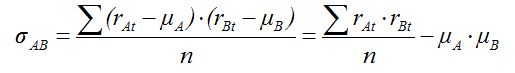
| rAt | rBt | rMt | rAt · rBt | |
| Día 1 | ||||
| Día 2 | -0,2500 | 0,1200 | -0,0687 | -0,0300 |
| Día 3 | 0,3333 | -0,2143 | 0,2131 | -0,0714 |
| Día 4 | 0,2500 | 0,1818 | 0,0135 | 0,0455 |
| SUMA | -0,0560 | |||
| Covarianza | -0,0219 |
de donde
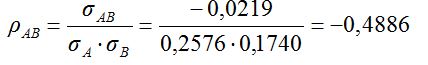
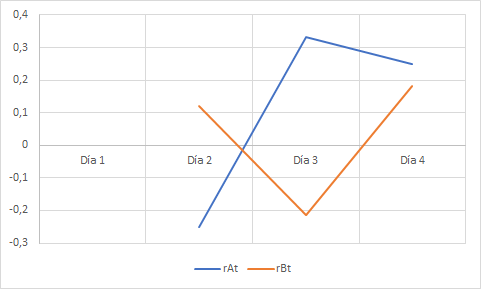
Los rendimientos de A y B exhiben una moderada correlación negativa porque, como muestra el gráfico inferior, evolucionan en sentido contrario.
La segunda variable a considerar es la composición de la cartera. Por ejemplo, si xA = 0,75 y xB = 0,25 obtenemos una cartera K con los siguientes estadísticos:
μK = 0,75 · 0,1111 + 0,25 · 0,0292 = 0,0906
σ2K = 0,752 · 0,0664 + 0,252 · 0,0303 + 2 · 0,75 · 0,25 · (-0,0219) = 0,0310
| XA | XB | σ2K | σK | μK |
| 1 | 0 | 0,0664 | 0,2576 | 0,1111 |
| 0,75 | 0,25 | 0,031 | 0,1761 | 0,0906 |
| 0,5 | 0,5 | 0,0132 | 0,1149 | 0,0701 |
| 0,25 | 0,75 | 0,013 | 0,1139 | 0,0497 |
Como quiera que los decisores no son indiferentes ante la combinación de riesgo y rendimiento, se plantea la necesidad de identificar combinaciones eficientes, que maximizan el rendimiento para un nivel dado de riesgo (o, a sensu contrario, que minimizan el riesgo para un rendimiento específico). Por ejemplo, aunque las dos últimas carteras tienen un riesgo esperado muy similar, es más atractiva la formada al 50% porque ofrece más rendimiento esperado.
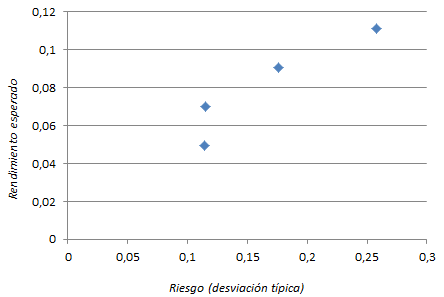
¿Y si la correlación no fuese negativa?
Los títulos A y B tienen correlación negativa, lo que significa que sus rendimientos tienden a evolucionar de forma antisimétrica: las combinaciones resultantes ofrecen rendimientos medios más estables, es decir, menos arriesgadas. Pudiera pensarse que la diversificación exige necesariamente que la asociación sea negativa, pero no es así. Para comprobarlo vamos a simular el comportamiento de la varianza para diferentes valores de ρ, ceteris paribus la composición de la cartera
Recuerde que el riesgo de la cartera es
σ2K = σ2A xA2 + σ2B · xB2 + 2 · σAB · xA · xB
Si combinamos A y B en proporciones arbitrarias del 50% podemos expresar la varianza como función de la correlación:
σ2K = 0,52 · 0,0664 + 0,52 · 0,0303 + 2 · 0,5 · 0,5 · σAB = 0,52 · 0,0664 + 0,52 · 0,0303 + 2 0,5 · 0,5 · [0,2576 · 0,1740 · ρAB]
ya que σAB = ρAB · σA · σB = 0,2576 · 0,1740 · ρAB. Evidentemente, diferentes niveles de correlación dan lugar a diferentes riesgos esperados porque ρ modula la mitigación: correlaciones elevadas causan una agregación explosiva del riesgo, y correlaciones muy negativas tienden a neutralizar la dispersión; lo realmente interesante es que los efectos de la diversificación se manifiestan incluso con correlaciones intermedias. Se sigue de ello que, a efecto de formar carteras, no solo debemos considerar la varianza de cada título sino también el grado en que contribuye a reducir o mitigar el riesgo de los restantes activos.
| ρAB | σAB | μK | σ2K |
| -1 | -0,0448 | 0,0701 | 0,0017 |
| -0,75 | -0,0336 | 0,0701 | 0,0074 |
| -0,5 | -0,0224 | 0,0701 | 0,0130 |
| -0,25 | -0,0112 | 0,0701 | 0,0186 |
| 0 | 0,0000 | 0,0701 | 0,0242 |
| 0,25 | 0,0112 | 0,0701 | 0,0298 |
| 0,5 | 0,0224 | 0,0701 | 0,0354 |
| 0,75 | 0,0336 | 0,0701 | 0,0410 |
| 1 | 0,0448 | 0,0701 | 0,0466 |
Para profundizar en el rol de las correlaciones vamos a explorar las oportunidades de diversificación en cuatro escenarios:
- Los rendimientos están perfecta y negativamente correlacionados
- La correlación es igual a cero
- La correlación es perfecta y positiva
- La correlación toma un valor positivo intermedio (ρ=0,5).
Escenario 1. Correlación perfecta negativa
Los estadísticos de las carteras son:
- μK = xA · 0,111 + xB · 0,0292 = 0,0906
- σ2K = xA2 · 0,0664 + xB2 · 0,0303 + 2 · 0,2576 · 0,1740 · (-1) · xA · xB = 0,0224
Son válidas cualesquiera combinaciones de valores no negativos que cumplan xA+xB= 1, entre ellas las siguientes: interesa especialmente una (xA = 0,4 y xB = 0,6) que ofrece un rendimiento esperado del 6,22% y un riesgo exactamente igual a cero. En el gráfico inferior esta cartera se corresponde con un punto situado sobre el eje de ordenadas, reflejando que σK = 0.
| XA | XB | σ2K | σK | μK |
| 1 | 0 | 0,0664 | 0,2576 | 0,1111 |
| 0,75 | 0,25 | 0,0224 | 0,1497 | 0,0906 |
| 0,5 | 0,5 | 0,0017 | 0,0418 | 0,0701 |
| 0,40 | 0,60 | 0,0000 | 0,0000 | 0,0622 |
| 0,25 | 0,75 | 0,0044 | 0,0661 | 0,0497 |
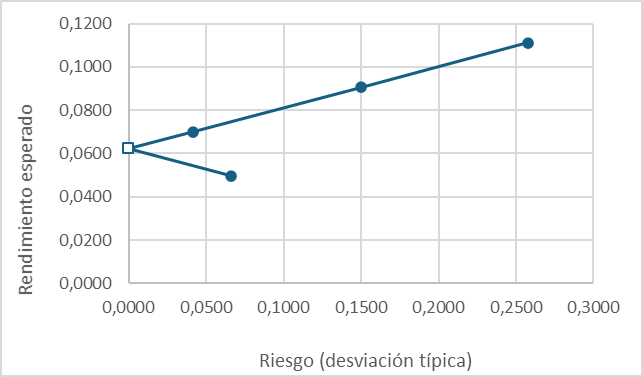
Cuando ρ = -1 puede hallarse una combinación con riesgo total nulo. La composición de la cartera puede obtenerse fácilmente derivando la expresión del riesgo, y resolviendo la expresión resultante al igualar dicha derivada a cero (primera condición de mínimo). Supuesto que el riesgo se formule en términos de A, la participación óptima de este título es
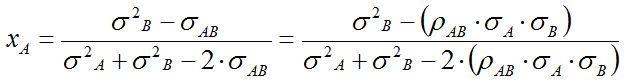
Como en este caso la correlación es igual a (-1), la expresión se reduce a
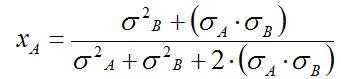
de donde resultan las proporciones ya conocidas: xA = 0,4031 y xB = 0,5969.
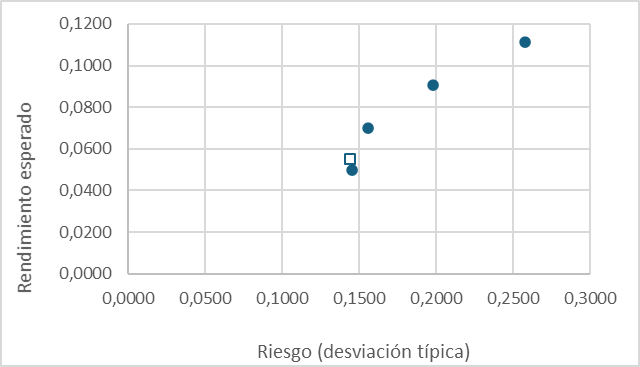
Escenario 2. Correlación nula
Vamos a recalcular los pronósticos de rendimiento y riesgo para las carteras anteriores, asumiendo ahora que ρAB = 0.
Las inversiones se sitúan ahora a lo largo de una curva (marcadores azules) que refleja la relación creciente entre rendimiento y riesgo; no hay ninguna combinación con riesgo cero, pero podemos identificar una cartera de mínimo riesgo absoluto (marcador cuadrado). Su composición se obtiene igualando a cero la primera derivada de la varianza (condición necesaria de mínimo) y recordando que en este caso ρ=0.
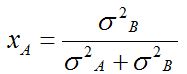
Operando, xB = σ2A / (σ2A+σ2B) = 0,6867, de donde xA = 0,3133. La desviación típica de esta cartera es σ = 0,1442.
| XA | XB | σ2K | σK | μK |
| 1 | 0 | 0,0664 | 0,2576 | 0,1111 |
| 0,75 | 0,25 | 0,0392 | 0,1980 | 0,0906 |
| 0,5 | 0,5 | 0,0242 | 0,1554 | 0,0701 |
| 0,25 | 0,75 | 0,0212 | 0,1455 | 0,0497 |
Observe que, incluso con una correlación no negativa, podemos beneficiarnos de los efectos de la diversificación.
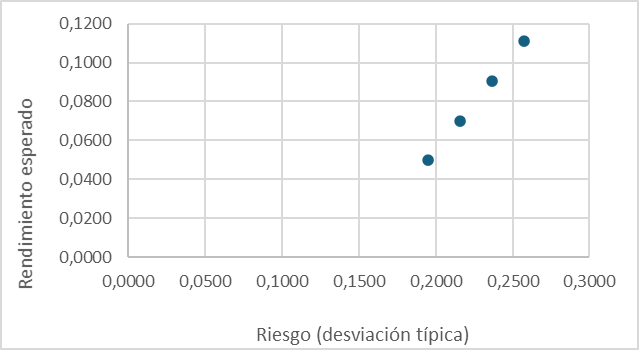
Escenario 3. Correlación perfecta positiva
Cuando ρ = 1, el riesgo de la cartera puede expresarse como una función lineal de la participación de uno de los títulos: la dispersión crece conforme se incrementa la inversión en el activo más arriesgado, de manera que no existen posibilidades de optimización y la mejor cartera es la constituida al 100% por el título menos volátil (en este caso, B)
| XA | XB | σ2K | σK | μK |
| 1 | 0 | 0,0664 | 0,2576 | 0,1111 |
| 0,75 | 0,25 | 0,0560 | 0,2367 | 0,0906 |
| 0,5 | 0,5 | 0,0466 | 0,2158 | 0,0701 |
| 0,25 | 0,75 | 0,0380 | 0,1949 | 0,0497 |
| 0 | 1 | 0,0303 | 0,1740 | 0,0292 |
Escenario 4. Correlación positiva, pero imperfecta
Como hemos comprobado, no es necesario que la correlación sea negativa para lograr al menos un cierto grado de diversificación combinando las acciones A y B. En realidad, la mayoría de los títulos tienen correlaciones positivas, pero intermedias. ¿Qué ocurre en este caso? ¿Podemos mitigar el riesgo? Vamos a repetir los cálculos anteriores, simulando una correlación ρAB = 0,5.
| XA | XB | σ2K | σK | μK |
| 1 | 0 | 0,0664 | 0,2576 | 0,1111 |
| 0,75 | 0,25 | 0,0476 | 0,2182 | 0,0906 |
| 0,5 | 0,5 | 0,0354 | 0,1881 | 0,0701 |
| 0,25 | 0,75 | 0,0296 | 0,1720 | 0,0497 |
| 0,1518 | 0,8482 | 0,0291 | 0,1705 | 0,0416 |
| 0 | 1 | 0,0303 | 0,1740 | 0,0292 |
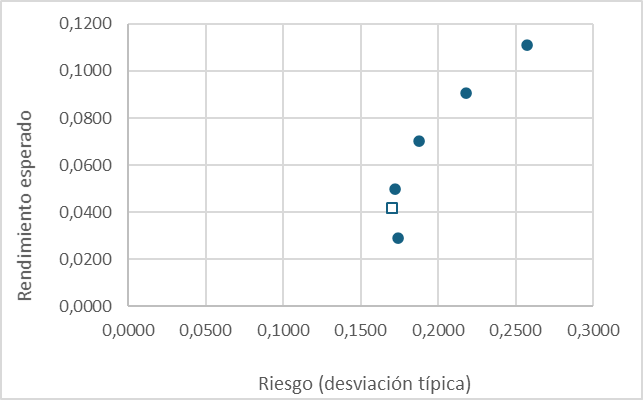
Nuevamente, aplicando las expresiones anteriores, podemos identificar una cartera de mínimo riesgo, que es la formada por xA = 0,1518 y xB = 0,8482, con σ = 0,1705.
En resumen...
La combinación de títulos en carteras proporciona siempre protección frente al riesgo, excepto en el hipotético (e irreal) caso de que las correlaciones entre los rendimientos sean exactamente iguales a uno. Las oportunidades de mitigar el riesgo son tanto mayores cuanto más pequeña es la correlación, y no es estrictamente necesario que ρ < 0.
| ρAB | XA | XB | σK | μK |
| -1,0000 | 0,4031 | 0,5969 | 0,0000 | 0,0622 |
| 0,0000 | 0,3133 | 0,6867 | 0,1442 | 0,0548 |
| 0,5000 | 0,1518 | 0,8482 | 0,1705 | 0,0416 |
| 1,0000 | 0 | 1,0000 | 0,1740 | 0,0292 |
Optimización con el modelo de Markowitz
El modelo para nuestros dos títulos implica minimizar la dispersión de la cartera, condicionada al cumplimiento de una meta arbitraria de rendimiento esperado:
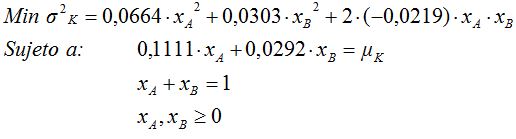
Las carteras resultantes, para rendimientos esperados entre el 3% y el 11%, son las siguientes:
| XA | XB | σ2K | σK | μK |
| 0,010 | 0,990 | 0,029 | 0,171 | 0,030 |
| 0,132 | 0,868 | 0,019 | 0,138 | 0,040 |
| 0,254 | 0,746 | 0,013 | 0,113 | 0,050 |
| 0,376 | 0,624 | 0,011 | 0,104 | 0,060 |
| 0,498 | 0,502 | 0,013 | 0,115 | 0,070 |
| 0,620 | 0,380 | 0,020 | 0,140 | 0,080 |
| 0,742 | 0,258 | 0,030 | 0,174 | 0,090 |
| 0,864 | 0,136 | 0,045 | 0,212 | 0,100 |
| 0,986 | 0,014 | 0,064 | 0,253 | 0,110 |
Como era previsible, a medida que aumenta el rendimiento exigido a la inversión lo hace también la participación del tíutlo A, que es el que tiene mayor rentabilidad esperada (pero también más riesgo, de ahí que el modelo priorice la participación de B para niveles bajos de μK). Esta no es, sin embargo, una regla general; recuerde que estamos considerando solo dos títulos que, además, tienen correlación negativa.
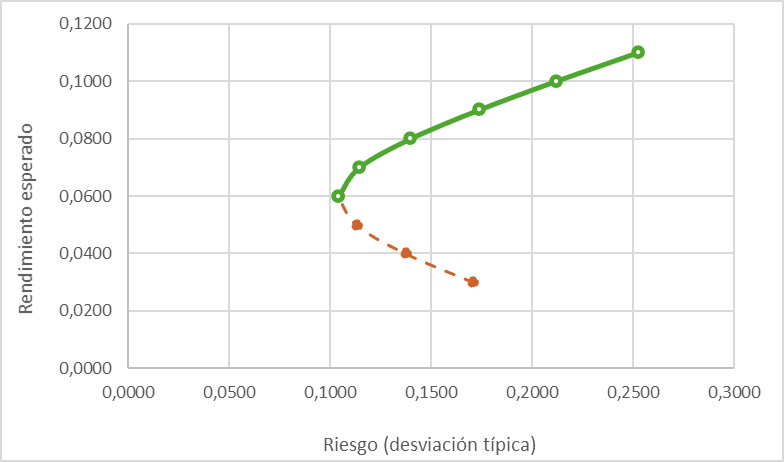
El gráfico inferior muestra la relación entre el riesgo, medido por la desviación típica, y el rendimiento esperado, para estas carteras diversificadas. Se sitúan a lo largo de una forma cuadrática, cuya rama inferior (en rojo) está dominada por la superior, que permite obtener un rendimiento superior para el mismo nivel de riesgo. Por ejemplo, podemos formar una cartera con un rendimiento esperado del 3% y un riesgo (medido por la desviación típica) del 17,10%; pero existe otra combinación que, con el mismo riesgo, permite aspirar a un rendimiento en torno al 9%.
La rama en verde es la frontera de carteras eficientes (FCE) del modelo de Markowitz, donde se sitúan las combinaciones que ofrecen la mejor expectativa de rendimiento, para un nivel dado de riesgo (o a sensu contrario, las combinaciones con menor riesgo, para un nivel dado de rentabilidad esperada).
La ecuación característica, o modelo de mercado
Continuando con los dos valores A y B considerados previamente, vamos a formular los correspondientes modelos de mercado
| PA | PB | Mercado | rAt | rBt | rMt | |
| Día 1 | 4 | 25 | 131 | |||
| Día 2 | 3 | 28 | 122 | -0,250 | 0,120 | -0,069 |
| Día 3 | 4 | 22 | 148 | 0,333 | -0,214 | 0,213 |
| Día 4 | 5 | 26 | 150 | 0,250 | 0,182 | 0,014 |
| Media | 0,111 | 0,029 | 0,053 | |||
| Varianza | 0,066 | 0,030 | 0,014 | |||
| Cuasivarianza | 0,100 | 0,045 | 0,021 | |||
| DT (poblac.) | 0,258 | 0,174 | 0,118 |
Los estimadores del modelo de mercado de A pueden obtenerse fácilmente como
βA = σAM / σ2M = 0,0247/0,0140 = 1,7627
αA = μA - βA · μM = 0,1111 - 1,7651 · 0,0526 = 0,0183
De manera más formal, también podemos resolver el siguiente sistema de ecuaciones (que se obtiene aplicando las condiciones necesaria y suficiente de mínimo a la suma de cuadrados de los errores de la estimación):
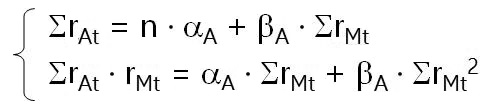
Los valores requeridos para estimar el modelo son:
- ΣrAt = 0,3333
- n = 3
- ΣrMt = 0,0526
- ΣrMt2 = 0,0503
- ΣrAt · ΣrMt = 0,0916
| PA | Mercado | rAt | rMt | rMt2 | rAt · rMt | |
| Día 1 | 4 | 131 | ||||
| Día 2 | 3 | 122 | -0,2500 | -0,0687 | 0,0047 | 0,0172 |
| Día 3 | 4 | 148 | 0,3333 | 0,2131 | 0,0454 | 0,0710 |
| Día 4 | 5 | 150 | 0,2500 | 0,0135 | 0,0002 | 0,0034 |
| Suma | 0,3333 | 0,1579 | 0,0503 | 0,0916 | ||
| Media | 0,1111 | 0,0526 | ||||
| Varianza pob. | 0,0664 | 0,0140 | ||||
| DT pob. | 0,2576 | 0,1183 |
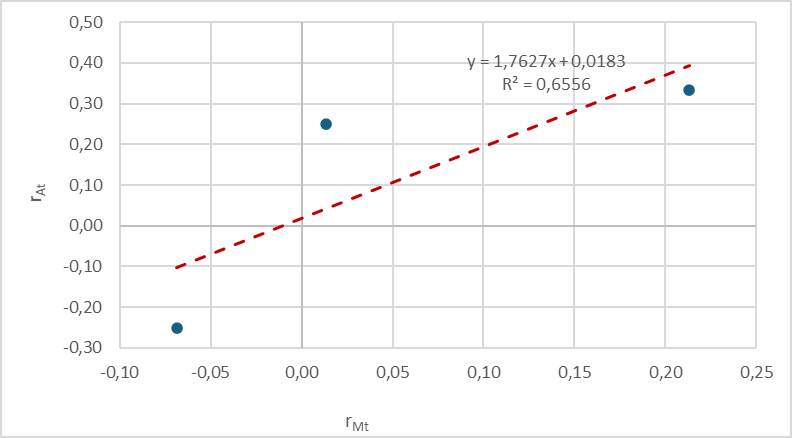
Resolviendo el sistema, se tiene que rAt = 0,0183 + 1,7627 · rMt.
El gráfico inferior muestra las observaciones reales (puntos azules), y el modelo de mercado (en trazo rojo); el coeficiente de determinación es únicamente aceptable, y se cometen errores de estimación apreciables.
Pronósticos para títulos, basados en el modelo de mercado
¿Cómo utilizaría la ecuación característica para formular pronósticos de rendimiento y riesgo?
σ2A = E(rAt - μA)2 = βA2 · σ2M + σ2εA = 1,76272 · 0,0140 + 0,0229 = 0,0664
ya que la varianza de los errores de estimación es σ2εA = SCEA / 3 = 0,0686 / 3 = 0,0229.
| rAt | rMt | rAt* | eAt | eAt2 | |
| Día 1 | |||||
| Día 2 | -0,25 | -0,0687 | 0,0183 + 1,7627 · (-0,0687)= = -0,1028 | -0,25 - (-0,1028) = = -0,1472 |
0,0217 |
| Día 3 | 0,3333 | 0,2131 | 0,394 | -0,0606 | 0,0037 |
| Día 4 | 0,25 | 0,0135 | 0,0421 | 0,2079 | 0,0432 |
| SCE | 0,0686 | ||||
| SCE / n | 0,0229 |
Observe que, cuando empleamos la ecuación característica, el riesgo de un título o cartera puede expresarse como la suma de dos componentes:
- Riesgo sistemático: βA2 · σ2M = 1,76272 · 0,0140 = 0,0435
- Riesgo específico, o diversificable: σ2εA = 0,0229
Estimadores para carteras
Al igual que los títulos individuales, las carteras tienen una ecuación característica que podemos emplear para formular pronósticos de rendimiento y riesgo. Vamos a construir las estimaciones correspondientes a las carteras anteriores, partiendo de los estimadores de las ecuaciones de los títulos A y B:
| Título | αj | βj | σ2jε |
| A | 0,0183 | 1,7627 | 0,0229 |
| B | 0,0994 | -1,3346 | 0,0053 |
Ya sabemos que la rentabilidad esperada es un promedio de las rentabilidades de los títulos, ponderado por sus respectivas participaciones en la cartera; el riesgo depende también de las participaciones, sin embargo en este caso vamos a formularlo empleando las respectivas ecuaciones características. Para ello, debe recordar que:
- La ordenada en el origen del modelo de mercado de la cartera es αK = Σαj · xj; por ejemplo para xA = 0,75 y xB = 0,25 se tiene αK = 0,0183 · 0,75 0,0994 · 0,25 = 0,0386
- La volatilidad es βK = Σβj · xj = 1,7627 · 0,25 + (-1,3346) · 0,25 = 0,9884
de manera que la ecuación característica de la inversión considerada es rKt = 0,0386 + 0,9884 · rMt. Con ella podemos formular un pronóstico para el rendimiento:
μK = 0,0386 + 0,9884 · μM = 0,0386 + 0,9884 · 0,0526 = 0,0906
si esperamos μM = 0,0526. El riesgo se define como la suma de las componentes sistemática y específica:
- Riesgo sistemático: βK2 · σ2M = 0,98842 · 0,0140 = 0,0137 si esperamos σ2M = 0,0140.
- Riesgo específico: Σσ2εj · xj2 = 0,0229 · 0,752 + 0,0053 · 0,252 = 0,0132
de manera que σ2K = 0,0137 + 0,0132 = 0,0269.
| XA | XB | βK | βj2 · σ2M | σ2εK | σ2K | σK | μK |
| 1 | 0 | 1,7627 | 0,0435 | 0,0229 | 0,0664 | 0,2576 | 0,1111 |
| 0,75 | 0,25 | 0,9884 | 0,0137 | 0,0132 | 0,0269 | 0,1639 | 0,0906 |
| 0,5 | 0,5 | 0,214 | 0,0006 | 0,007 | 0,0077 | 0,0877 | 0,0701 |
| 0,25 | 0,75 | -0,5603 | 0,0044 | 0,0044 | 0,0939 | 0,0939 | 0,0497 |
Gestionando el riesgo
Los modelos de mercado son una herramienta esencial para evaluar el riesgo de los títulos y diseñar carteras adecuadas a nuestras expectativas.
Por ejemplo, podemos plantearnos si existe la posibilidad de formar una combinación A+B completamente libre de riesgo. Como sabemos esto es matemáticamente inviable porque exigiría que la correlación entre ambos fuese exactamente igual a -1, pero podemos reducir sustancialmente la exposición: es fácil comprobar que la cartera de mínimo riesgo, de entre todas las que se pueden formar combinando A y B, es la constituida por xA = 0,3715 y xB = 0,6285: esta inversión posee una varianza σ2K = 0,0109 y un rendimiento esperado μK = 0,0596; su beta es βK = -0,1839 (es superdefensivo), riesgo sistemático igual a 0,0005 y riesgo específico 0,0053.
Por el contrario, las características concretas de estos dos títulos sí nos permiten diseñar una cartera completamente libre de riesgo sistemático (aunque, como veremos más adelante, esto puede ser absurdo):
βK = xA · βA + xB · βB = xA · βA + (1-xA) · βB = xA · 1,7627 + (1 - xA) · (-1,3346) = 0 → xA = 0,4309 y xB = 0,5691.
Esta es una cartera beta-neutral, cuyo rendimiento no proviene de la exposición al riesgo sistemático sino de la alfa de su ecuación característica; observe que a pesar de todo, tiene riesgo, exclusivamente específico (σ2K = σ2εK = 0,0060).
También podemos diseñar una cartera que replique, en promedio, el comportamiento del rendimiento del mercado. Es preciso que su beta sea igual a uno, y para ello debemos distribuirla en xA = 0,7538 y xB = 0,2462; su riesgo sistemático es idéntico al del mercado (RS = 0,0273), tiene además un riesgo específico RE = 0,0133 con σ2K = 0,0273 y μK = 0,0909.
El modelo de Sharpe
Aunque las carteras beta neutrales e índice tienen notable importancia práctica, con frecuencia los inversores están interesados en optimizar la cartera en función de un determinado objetivo de rentabilidad. El modelo de Markowitz nos permite solucionar este problema, a costa de un importante volumen de cálculos que crece conforme consideramos más títulos.
Una alternativa es considerar el uso de las ecuaciones característicsas de los títulos, lo que conduce a una manera diferente de estimar el rendimiento y riesgo de las carteras. El modelo resultante, sugerido por Sharpe, convierte la matriz de varianzas y covarianzas en una matriz diagonal unidad:
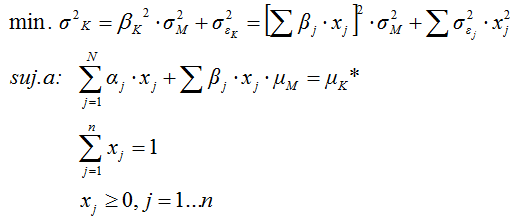
Estimamos la varianza de la perturbación aleatoria (σ2εj ) a través de la varianza de los errores de estimación.
Para el título A (cuyo modelo de mercado es rAt = 0,0183 + 1,7627 · rMt) se tiene que, σ2εA = SCEA / 3 = 0,0686 / 3 = 0,0229.
| rA | rMt | rAt* | eAt | eAt2 | |
| Día 1 | |||||
| Día 2 | -0,2500 | -0,0687 | -0,1028 | -0,1472 | 0,0217 |
| Día 3 | 0,3333 | 0,2131 | 0,3940 | -0,0606 | 0,0037 |
| Día 4 | 0,2500 | 0,0135 | 0,0421 | 0,2079 | 0,0432 |
| SCE(A) = | 0,0686 | ||||
| σ2εA= | 0,0229 |
Análogamente, σ2εB = SCEB / 3 = 0,0160 / 3 = 0,0053. El modelo de Sharpe queda como sigue:
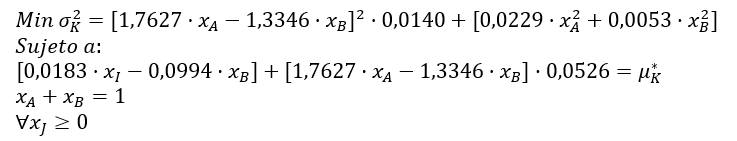
y su solución es también paramétrica, es decir, identifica una cartera óptima para cada valor μK*.