
Una red de neuronas artificiales
Los sistemas basados en inteligencia artificial replican comportamientos que consideramos inteligentes, por lo que implican en términos de capacidad para adquirir y actializar conocimientos, y emplearlo creativamente para evaluar situaciones o diagnosticar problemas.
Las redes de neuronas artificiales (RNA) almacenan este conocimiento de manera implícita, en una estructura de elementos de procesamiento (neuronas), conectados a través de un entramado de relaciones cuyo diseño permite que algunas neuronas estén activas o inactivas en función de la naturaleza e intensidad de los estímulos que reciben. La red adquiere el conocimiento a través de un proceso de entrenamiento, en el que se le presentan casos (definidos por las variables de entrada, por ejemplo ratios financieras) y la salida o diagnóstico deseado (por ejemplo, la empresa es pagadora); una vez comprobado que el aprendizaje es correcto, la red puede ser empleada para realizar diagnósticos y también para formular pronósticos. La principal fortaleza de las RNA es su capacidad para detectar variables y relaciones implícitas en los datos; por tanto, la red no se limita a utilizar mecánicamente los datos que se le aportan: es capaz de interpretarlos, de inferir nuevo conocimiento, y de utilizarlo para diagnosticar nuevos casos, de manera similar a como hacen las personas a quienes atribuimos experiencia o competencia profesional.
Vamos a entrenar una red neuronal simple, concretamente una red de perceptrones multicapa, con las empresas pagadoras y fallidas que hemos empleado más arriba para ilustrar el uso del análisis discriminante. Nuestra red va a tener una sola capa oculta con 10 neuronas; la capa de entrada tendrá dos elementos (uno por cada ratio) y la de salida otros dos (uno por cada estado: pagadora, o morosa). Haremos que nuestra red aprenda empleando el algoritmo de momentum, presentándole los casos uno a uno (on-line). La tabla inferior muestra los resultados de nuestra red (MLP-1-O-M) y de otros diseños alternativos:
- Un perceptrón multicapa con aprendizaje basado en el algoritmo Levenberg-Marquardt y presentación conjunta (batch) de la muestra de aprendizaje
- Una red probabilística
- Una red generalizada (retroalimentada)
- Una máquina de soporte vectorial
Es importante tener en cuenta que el aprendizaje con una muestra tan pequeña es simplemente imposible, y que de hecho es muy probable que la red esté sobreentrenada - es decir, que en lugar de inferir patrones haya aprendido los casos -; los resultados mostrados a continuación pretenden una finalidad meramente ilustrativa.
| MODELO | Entrenamiento | Validación cruzada | ||||
| Erorr est. | Correlación | Aciertos | Error est. | Correlación | Aciertos | |
| Perceptrón multicapa MLP 1-O-M | 0,1673 | 0,5752 | 77,78% | 0,0470 | 0,9427 | 100% |
| Perceptrón multicapa 1-B-L | 0,1819 | 0,5325 | 66,67% | 0,0102 | 0,9883 | 100% |
| Red neural probabilística 0-N-N | 0,1810 | 0,6790 | 77,78% | 0,1919 | 0,7992 | 66,67% |
| Red generalizada 1-B-L | 0,0152 | 0,9697 | 100% | 0,0022 | 0,9982 | 100% |
| Máquina de soporte vectorial 0-N-N | 0,0748 | 0,8872 | 100% | 0,2052 | 0,6556 | 66,67% |
Nuestra red (MLP 1-O-M) logra una tasa de acierto del 78% en el entrenamiento, y del 100% en la de validación cruzada, lo que en principio es satisfactorio. Las matrices de confusión nos ayudan a comprender cómo se comporta la red: en la fase de entrenamiento la red acierta el 100% de los casos de empresas sanas, pero falla en un 22% de los casos de morosas (que son calificadas como pagadoras: por tanto, comete una proporción bastante alta de errores de tipo I); en la validación cruzada, no se cometen errores de clasificación.
| Entrenamiento | Validación cruzada | |||||||
| Pronóstico | Pronóstico | |||||||
| Pagador | Moroso | Pagador | Moroso | |||||
| Estado real | Pagador | 22,22% | 0,00% | Estado real |
Pagador | 66,67% | 0,00% | |
| Moroso | 22,22% | 55,56% | Moroso | 0,00% | 33,33% | |||
La red nos ofrece también estimaciones del peso relativo de cada variable de entrada en el diagnóstico final. La ratio de tesorería parece ser la más relevante, especialmente de cara a clasificar a una empresa como morosa - por tanto la red infiere que son más importantes las tensiones de tesorería que el nivel de endeudamiento -.
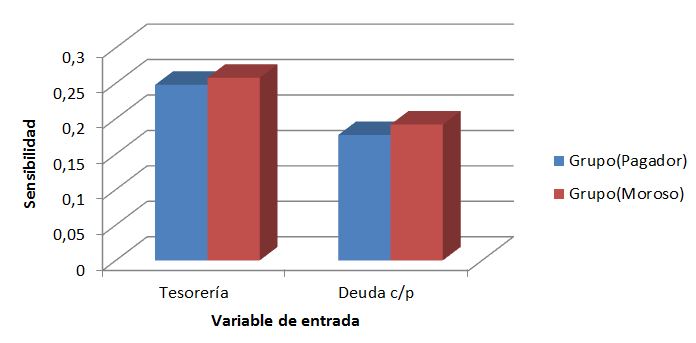
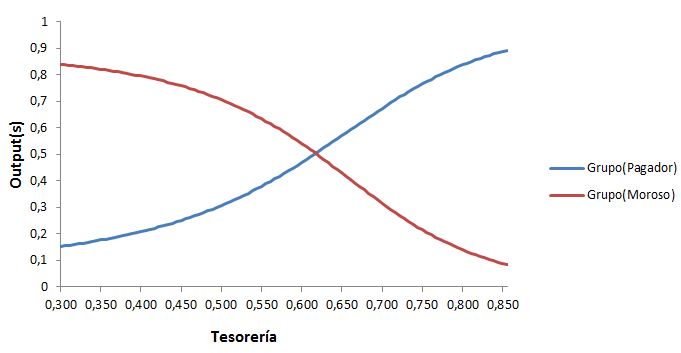
También podemos conocer la incidencia relativa de los valores de cada variable, es decir: un aumento en la tesorería, ¿aumenta, o reduce la verosimilitud de que la empresa sea clasificada como potencialmente morosa? La relación entre tesorería y riesgo de morosidad, ¿es lineal, exponencial, acumulativa...? La red sugiere que los valores más elevados de la tesorería son claramente determinantes, y que su incidencia en el riesgo es acumulativa (una pequeña variación positiva en la ratio de tesorería incrementa sustancialmente la verosimilitud de que la empresa sea pagadora; a sensu contrario, una pequeña disminución en esa ratio aumenta rápidamente las sospechas de una potencial conducta morosa); los signos de las relaciones son los esperados (mayor tesorería se corresponde con mayor verosimilitud de resultar clasificado como pagador); también son correctos los signos estimados para el nivel de deuda, si bien la incidencia de esta variable parece ser más o menos proporcional al apalancamiento.

Pero recuerde que el objetivo de la red no es únicamente adquirir conocimiento y proporcionar explicaciones sino, también, formular pronósticos. En el caso de nuestro nuevo cliente, con tesorería = 0,5 y endeudamiento a corto plazo = 0,9, la red proporciona las siguientes puntuaciones:
- Para el output pagador, una puntuación igual a 0,36
- Para el output moroso, una puntuación igual a 0,65
de manera que deberíamos entender que el cliente es potencialmente fallido, en concordancia con lo advertido por el modelo discriminante.